文字搜尋引擎已趨向穩定,大致可以分為:抓取部分、前置處理部分、索引部分、搜索部分、使用者介面
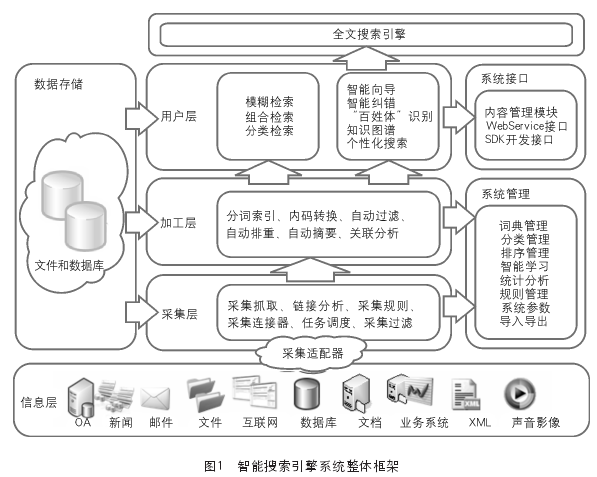
今天先來介紹前置處理部分!
文字前置處理
網頁自動尋檢程式(Spider)抓取的資料在進行某種程度的前置處理文後才能用於索引的建立。文字資料前置處理主要是為了分析詞語而進行的文宇分析,而文字分析又可分為分詞、語言處理等過程。
- 單詞分割:首先,將文本按照單詞逐個分開。例如,將句子 "Hello, world!" 分成單詞 "Hello"、","、和 "world"。
- 標點符號去除:接著,我們通常會移除文本中的標點符號,因為它們通常不包含特定的意義,而且在搜索或分析中不常用。舉例來說,"Hello," 可能會被處理成 "Hello"。
- 停用詞去除:最後,我們會去除停用詞。停用詞是語言中常見且無特殊意義的單詞,如 "the"、"and"、"in" 等。這些詞語通常不用於搜索關鍵字,因此在索引建立過程中會被排除。
文字分詞過程有助於準備文本數據以進行後續的搜索或分析,同時可以減小索引的大小並提高搜索的效率。
-
語言處理
是對文字分詞後的詞元進行語言相關的處理,以提取詞的基本形式或根據語言規則進行轉化。以英文為例,進行語言處理的主要步驟包括:
- 小寫轉換:將詞元轉換為小寫字母,以確保不同大小寫形式的詞在處理中被視為相同。例如,將 "Books" 轉換為 "books"。
單字縮減:
- 詞幹分析(Stemming):進行詞幹分析時,使用特定的演算法來提取詞的詞幹或詞根形式。詞幹是單詞的基本形式,通常是去除詞尾,以得到單詞的通用形式。例如,將 "running" 轉換為 "run"。
- 詞形還原(Lemmatization):詞形還原是通過查詢詞典或使用語言規則,將詞元還原為其基本形式。這可以確保單詞被轉換為正確的基本詞彙形式。例如,將 "better" 還原為 "good"。
這兩種處理方式有時會交集,意味著它們可能都會將同一個詞轉換為相同的基本形式。不過,詞幹分析通常是基於演算法進行的,而詞形還原則更傾向於使用字典或語言規則。兩者的目標都是確保詞元以一致的方式表示,以便後續的文本分析和搜索。
參考資料:深智數位《CV+AI自己動手完成圖像搜尋引擎》

